康宁光通信:光纤连接如何推动生成式人工智能革命-九游会旧版
光纤在线编辑部 2024-01-29 14:08:24 文章来源:本站消息 九游会官网登录入口网页的版权所有,未经许可严禁转载.


导读:当你想到人工智能时,脑中会浮现什么?想必多数情况下您会第一时间想到chatgpt,而在它成功的背后,光纤对生成式人工智能的支持也是不可或缺。最近,来自康宁的mustafa keskin对光纤与生成式人工智能之间的联系做了技术分析。
1/29/2024,光纤在线讯,当你想到人工智能时,脑中会浮现什么?
早在半年前,chatgpt就能够像人类一样提供答案,这些答案既符合语境,又具有技术上的合理性。但人工智能局限性也很明显,它会以要点形式给出回答,但实际上只是一个ai模型。
现在,当你在chatgpt上输入一个问题时,它的反应已经十分迅速,对此,chatgpt的创建者们实现了哪些改变?
最有可能的情况是,为满足超过1亿用户的需求,openai扩展了其人工智能集群的推理能力。据报道,在人工智能芯片制造商中处于领先地位的英伟达(nvidia)已供应大约20,000个图形处理单元(gpu),用于支持chatgpt的开发,且有大幅增加图形处理单元使用的计划。有人推测,他们即将推出的人工智能模型可能需要多达1000万个图形处理单元。
gpu集群架构:生成式人工智能的基础
理解20,000个gpu的概念是容易办到的,但通过1000万个gpu的光连接来执行智能任务很具有挑战性。
如何先配置好较小的单元,逐渐将其扩大至包含数千个gpu的集群?我们以基于传统的超算(hpc)网络而编写的英伟达设计指南为例。
根据设计指南的建议,该过程使用多个具有256个gpu pod的较小单元(可扩展单元)来构建大量gpu集群。每个pod由8个服务器机架和2个网络机架(位于一排机柜中间位置)组成。这些pod内部以及相互之间的连接通过infiniband(部署在英伟达的quantum-2交换机上的高速、低延迟交换协议)协议建立。
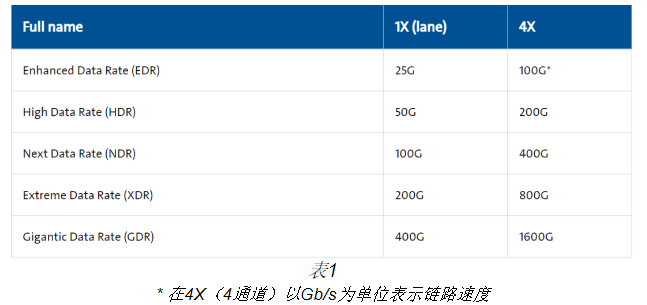
当前的infiniband交换机使用32个800g osfp收发器,采用400g(ndr)双端口。每个端口使用8芯光纤,因此每台交换机有64x400g端口。且即将到来的新一代交换机,很大可能将采用xdr端口。这意味着每台交换机将有64x800g端口,每个端口也使用8芯光纤(主要是单模光纤)。
如表1所示,该4通道(8芯光纤)模式在infiniband路线图中反复出现,且未来将使用更快的速度。
就布线而言,在超算(hpc)领域普遍采用的最佳做法是:采用点对点有源光缆(aoc)。然而,随着(mpo)光纤连接器接口的最新ndr端口的推出,点对点连接的情形已从aoc光缆转变为mpo-mpo无源跳线。在考虑单个具有256个gpu的pod时,利用点对点连接没有什么大问题。但是在追求更大的规模时就遇到了问题,例如16k gpu需要64个具有256个gpu的pod实现互连。这些高性能gpu集群使用的计算结构对于线路路由优化有极高的要求。在线路路由优化设置中,来自每个计算系统的所有主机通道适配器(hca)均连接至同一个叶交换机(leaf switch)。
据说该设置对于最大限度提高深度学习(dl)训练性能至关重要。一个标准的h100计算节点配备4个双端口osfp,转换为8个上行链路端口(每个gpu一个独立上行链路)与八个不同的叶交换机连接,由此建立一个8条线路优化结构。
该设计在处理单个具有256个gpu的pod时可以无缝工作。但如果目标是构建一个包含16,384个gpu的集群时该怎么办?在这种场景中,有必要增加两个交换层:来自每个pod的第一个叶交换机与脊交换机组一(sg1)中的每个交换机连接,每个pod内的第二个叶交换机与脊交换机组二(sg2)中的每个交换机连接,以此类推。为取得完全实现的胖树(fat-tree)拓扑结构,必须加入第三层核心交换组(cg)。
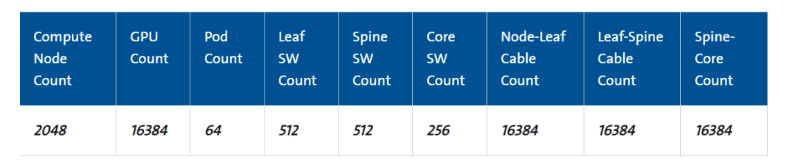
让我们回顾一下16,384个gpu集群的光缆连接数量。计算节点和叶交换机之间建立连接需要16,384根光缆,每个pod有256根mpo跳线。在开始网络拓展的过程时,建立叶-脊连接和脊-核心连接的任务变得更具有挑战性。涉及到先捆扎多根mpo跳线,然后将其敷设50米至500米不等的距离。
有没有更高效的运营方式?一个建议是采用结构化布线系统,该系统采用两个接线板设计,利用大芯数mpo干线,可能采用144根光纤。这样就能把18根mpo跳线(18x8=144)合并成一根干线光缆,一次敷设完成。通过在端点使用合适的mpo适配器面板,可将它们拆开为多根8芯光缆,并与恰当的线路连接,避免捆绑多根mpo跳线带来的复杂度。
对于一个非阻塞结构,每个pod需要256条上行链路。我们可选择从每个pod拉出15x144根光纤干线,产生270(15x18)上行链路(只需使用15个大芯数线缆)。另外,该设置提供14(270-256)个备用连接,可作备份或用于存储或管理网络连接。
人工智能在理解问题方面取得了重大进展。就实现这种转变而言,寻求能够支持广泛gpu集群(包括16k gpu或24k gpu)的布线九游会旧版的解决方案,是这一难题的重要组成部分,也是光连接行业面临的挑战。
早在半年前,chatgpt就能够像人类一样提供答案,这些答案既符合语境,又具有技术上的合理性。但人工智能局限性也很明显,它会以要点形式给出回答,但实际上只是一个ai模型。
现在,当你在chatgpt上输入一个问题时,它的反应已经十分迅速,对此,chatgpt的创建者们实现了哪些改变?
最有可能的情况是,为满足超过1亿用户的需求,openai扩展了其人工智能集群的推理能力。据报道,在人工智能芯片制造商中处于领先地位的英伟达(nvidia)已供应大约20,000个图形处理单元(gpu),用于支持chatgpt的开发,且有大幅增加图形处理单元使用的计划。有人推测,他们即将推出的人工智能模型可能需要多达1000万个图形处理单元。
gpu集群架构:生成式人工智能的基础
理解20,000个gpu的概念是容易办到的,但通过1000万个gpu的光连接来执行智能任务很具有挑战性。
如何先配置好较小的单元,逐渐将其扩大至包含数千个gpu的集群?我们以基于传统的超算(hpc)网络而编写的英伟达设计指南为例。
根据设计指南的建议,该过程使用多个具有256个gpu pod的较小单元(可扩展单元)来构建大量gpu集群。每个pod由8个服务器机架和2个网络机架(位于一排机柜中间位置)组成。这些pod内部以及相互之间的连接通过infiniband(部署在英伟达的quantum-2交换机上的高速、低延迟交换协议)协议建立。
当前的infiniband交换机使用32个800g osfp收发器,采用400g(ndr)双端口。每个端口使用8芯光纤,因此每台交换机有64x400g端口。且即将到来的新一代交换机,很大可能将采用xdr端口。这意味着每台交换机将有64x800g端口,每个端口也使用8芯光纤(主要是单模光纤)。
如表1所示,该4通道(8芯光纤)模式在infiniband路线图中反复出现,且未来将使用更快的速度。
就布线而言,在超算(hpc)领域普遍采用的最佳做法是:采用点对点有源光缆(aoc)。然而,随着(mpo)光纤连接器接口的最新ndr端口的推出,点对点连接的情形已从aoc光缆转变为mpo-mpo无源跳线。在考虑单个具有256个gpu的pod时,利用点对点连接没有什么大问题。但是在追求更大的规模时就遇到了问题,例如16k gpu需要64个具有256个gpu的pod实现互连。这些高性能gpu集群使用的计算结构对于线路路由优化有极高的要求。在线路路由优化设置中,来自每个计算系统的所有主机通道适配器(hca)均连接至同一个叶交换机(leaf switch)。
据说该设置对于最大限度提高深度学习(dl)训练性能至关重要。一个标准的h100计算节点配备4个双端口osfp,转换为8个上行链路端口(每个gpu一个独立上行链路)与八个不同的叶交换机连接,由此建立一个8条线路优化结构。
该设计在处理单个具有256个gpu的pod时可以无缝工作。但如果目标是构建一个包含16,384个gpu的集群时该怎么办?在这种场景中,有必要增加两个交换层:来自每个pod的第一个叶交换机与脊交换机组一(sg1)中的每个交换机连接,每个pod内的第二个叶交换机与脊交换机组二(sg2)中的每个交换机连接,以此类推。为取得完全实现的胖树(fat-tree)拓扑结构,必须加入第三层核心交换组(cg)。
让我们回顾一下16,384个gpu集群的光缆连接数量。计算节点和叶交换机之间建立连接需要16,384根光缆,每个pod有256根mpo跳线。在开始网络拓展的过程时,建立叶-脊连接和脊-核心连接的任务变得更具有挑战性。涉及到先捆扎多根mpo跳线,然后将其敷设50米至500米不等的距离。
有没有更高效的运营方式?一个建议是采用结构化布线系统,该系统采用两个接线板设计,利用大芯数mpo干线,可能采用144根光纤。这样就能把18根mpo跳线(18x8=144)合并成一根干线光缆,一次敷设完成。通过在端点使用合适的mpo适配器面板,可将它们拆开为多根8芯光缆,并与恰当的线路连接,避免捆绑多根mpo跳线带来的复杂度。
对于一个非阻塞结构,每个pod需要256条上行链路。我们可选择从每个pod拉出15x144根光纤干线,产生270(15x18)上行链路(只需使用15个大芯数线缆)。另外,该设置提供14(270-256)个备用连接,可作备份或用于存储或管理网络连接。
人工智能在理解问题方面取得了重大进展。就实现这种转变而言,寻求能够支持广泛gpu集群(包括16k gpu或24k gpu)的布线九游会旧版的解决方案,是这一难题的重要组成部分,也是光连接行业面临的挑战。
关键字: 康宁

光纤在线公众号
更多猛料!欢迎扫描左方二维码关注光纤在线官方微信更多关于 康宁 的新闻
- (01-26)
- 光纤连接如何推动生成式人工智能革命 (01-24)
- 康宁预测2024年数据中心发展三大趋势 (01-22)
- pure storage:2024年人工智能和可持续将推动中国市场技术应用与人才发展变革 (01-22)
- marvell硅基光电子及异质集成技术的创新突破:面向人工智能应用的光引擎 (01-19)
- 2024年数据中心发展预测:三大趋势凸显 (01-16)
- (01-15)
- (12-18)
- (12-12)
- (12-12)